AFL阅读文档
AFL在github上下载链接:https://github.com/mirrorer/afl (然后编译安装make+make install)
AFL工具大致流程
1)将用户提供的初始测试案例加载到队列中
2)从队列中取出下一个输入文件
3)尝试最小程度的修改测试案例而不改变程序标准的行为
4)使用平衡、研究充分的传统模糊测试策略反复改变文件
5)如果生成的变化导致程序的状态改变被仪器记录,将改变后的输出作为队列的新输入
6)跳到2
简单的使用
当有源代码时,可以用自带的工具来标准的编译第三方代码,替代gcc或者clang
1 | $ CC=/path/to/afl/afl-gcc ./configure |
静态构建(绑定.so文件等,可以通过设置LD_LIBRARTY_PATH)
1 | $ CC=/path/to/afl/afl-gcc ./configure --disable-shared |
make时,设置AFL_HERDEN=1检测内存错误能力更强
Libdislocator可以帮助发现堆相关问题
检测可执行程序可以使用QEMU形式
1 | $cd qemu_mode |
testcases/子目录里面有很多例子,当数据很多时,可以使用AFL-cmin,用来识别功能
不同的文件
模糊测试文件由afl-fuzz程序执行
语法
1 | $ ./afl-fuzz -i 测试案例集 -o 结果 文件路径 [...参数...] |
fuzz输出文件解释
fuzz完成后会在fuzz_out文件夹中生成三个文件夹,分别为queue、crashes、hangs
queue文件夹中存放的文件为测试案例,可以使用afl-cmin将其缩小
crashes文件夹中存放了可以导致程序崩溃的样例(当测试程序收到某些致命错误时,如SIGSEGV、SIGILL、SIGABRT)
hangs中存放了导致测试程序超时的案例(1s和-t参数中的较大值),可以通过修改AFL_HANG_TMOUT调整
当无法重现afl-fuzz发生的崩溃时,可能的原因是没有设置与该工具使用的相同的内存限制。
解决方法
1 | $ LIMIT_MB=50 |
fuzz界面解释
① Process timing:Fuzzer运行时长、以及距离最近发现的路径、崩溃和挂起经过了多长时间。
② Overall results:Fuzzer当前状态的概述。
③ Cycle progress:我们输入队列的距离。
④ Map coverage:目标二进制文件中的插桩代码所观察到覆盖范围的细节。
⑤ Stage progress:Fuzzer现在正在执行的文件变异策略、执行次数和执行速度。
⑥ Findings in depth:有关我们找到的执行路径,异常和挂起数量的信息。
⑦ Fuzzing strategy yields:关于突变策略产生的最新行为和结果的详细信息。
⑧ Path geometry:有关Fuzzer找到的执行路径的信息。
⑨ CPU load:CPU利用率
afl及相关工具安装
afl-fuzz
afl-fuzzing项目地址:
1 | https://github.com/mirrorer/afl |
安装及配置
1 | apt-get update |
afl-fuzz++安装
1 | sudo apt-get update |
crash exploration mode
afl-fuzz自带的运行模式,用于分析crashes利用的可行性,可以根据生成的crashes文件,产生不同的crashes
1 | afl-fuzz -m none -C -i poc -o peruvian-were-rabbit_out -- ~/src/LuPng/a.out @@ out.png |
afl-cmin和afl-tmin
afl-cmin作用是移除执行相同代码的输入文件,在测试的时候有可能会用到多个测试案例,此时就可以使用afl-cmin精简输入文件
1 | Required parameters: |
afl-tmin作用是减小单个文件的大小
1 | equired parameters: |
fuzz测试案例
fuzz需要有测试案例,通过案例的变异,可以使程序crash,然后进行相关操作,一般使用项目自带的案例,或者是afl中的案例,除此
之外还有开源的语料库可供使用,如下
afl generated image test sets
fuzzer-test-suite
samples-libav
fuzzdata
moonlight
afl-gcc和afl-g++构建项目
在fuzz过程中,一般需要构建项目两次,第一次是使用afl自带的afl-gcc或者afl-g++以及afl-clang等,来源码中插桩,并测试
程序的crashes,第二次为出现crashes时,使用gdb进行调试
编译器等设置如下
1 | ./configure CC="afl-gcc" CXX="afl-g++" |
下载项目后,此时得到的只是源代码、及相关文件部分,还需要编译等操作(对应项目目录)
流程
1 | git clone https://github.com/program-examples |
当需要重新编译时,需要删除原来的文件,操作
1 | rm -r $HOME/fuzzing_test/install |
afl-showmap
使用afl-showmap可以在fuzz前后测试程序的输出等信息
用法
1 | afl-showmap [ options ] -- /path/to/target_app [ ... ] |
使用例子
1 | afl-showmap -m none -o /dev/null -- $HOME/fuzzing_xpdf/install/bin/pdftotext $HOME/fuzzing_xpdf/out/default/crashes/test.pdf |
结果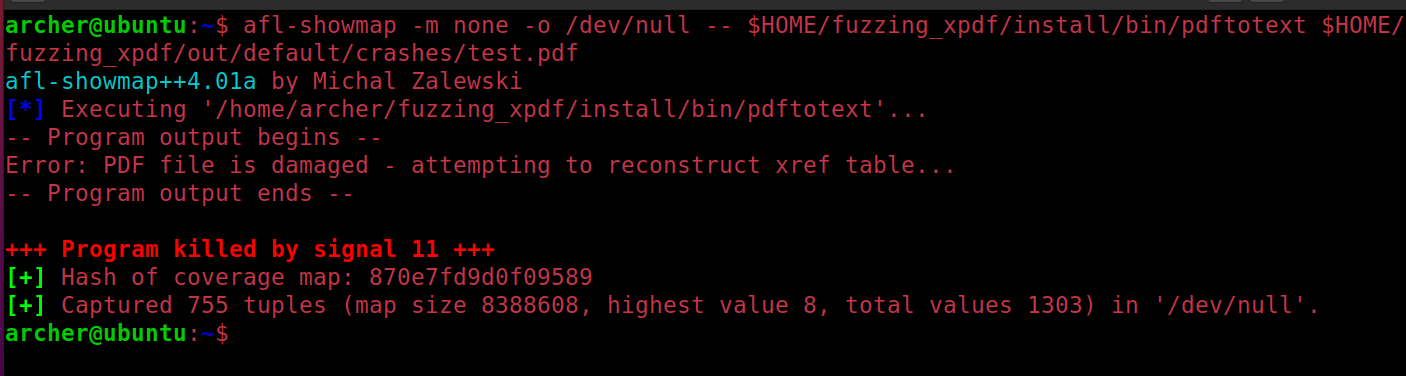
crasheswalk
分析crashes原因的工具
安装方式
1 | $ apt-get install gdb golang |
当go get这一步装不上时见blog.csdn.net
screen
使用screen命令可以暂停或者恢复fuzzing工作
用法如下
1 | screen afl-fuzz ...... |
具体的用法参考:https://www.runoob.com/linux/linux-comm-screen.html
相关参数
如下
1 | afl-fuzz [ options ] -- /path/to/fuzzed_app [ ... ] |
afl-fuzz相关原理
afl主要的用途是对与c/c++程序进行模糊测试,可以对存在源码和不存在源码的程序(qemu_mode)进行分析,白盒测试效率远远高于黑盒。
afl测试程序流程,如图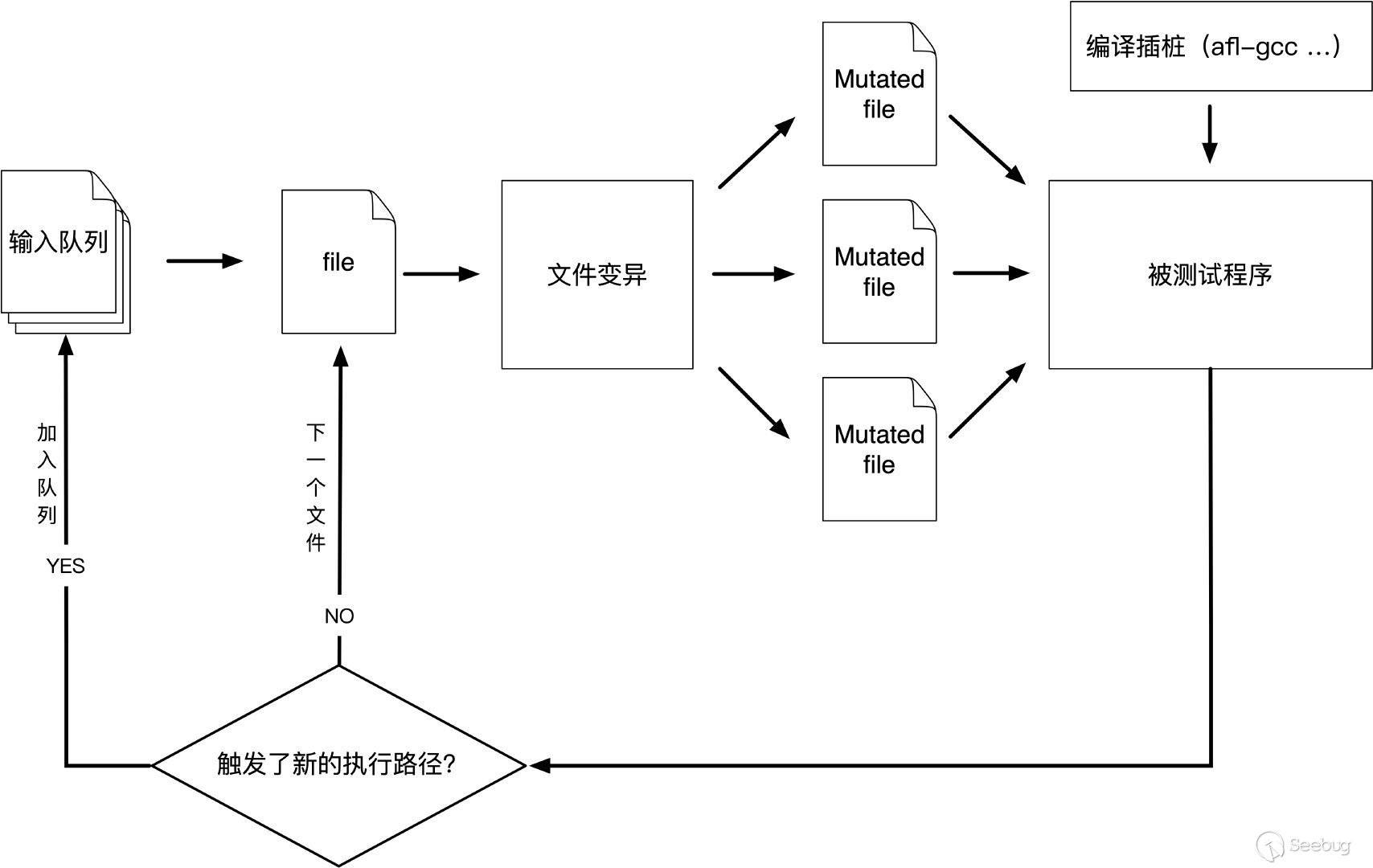
1.从源码编译程序时进行插桩,以记录代码覆盖率(Code Coverage);
2.选择一些输入文件,作为初始测试集加入输入队列(queue);
3.将队列中的文件按一定的策略进行”突变”;
4.如果经过变异文件更新了覆盖范围,则将其保留添加到队列中;
5.上述过程会一直循环进行,期间触发了crash的文件会被记录下来。
插桩的原理
在编译过程中,使用afl-gcc等afl工具编译项目,会对源码(.s)进行插桩,插桩的规则位,在main函数入口,函数入口,条件跳转等处插桩,直接插入一段汇编代码
这一段汇编代码如下
trampoline_fmt_64如下
1 | static const u8* trampoline_fmt_64 = |
在main函数入口处插入的汇编代码段为
1 | static const u8* main_payload_64 = |
main_payload_64中插入了很多afl类的函数,方便调用
有源码的情况
将源码编译生成.s文件,然后对.s文件插桩,最后生成插桩后的文件modifed_file
插桩的位置有如下情况
1.条件跳转指令(jne\je\jle等)
2.main函数入口
3.function入口
条件:
1.只在代码段插桩
2.只对AT&T汇编插桩(intel跳过)