v8的组成
v8主要由这四个模块组成:
1.Parser:解析器将javascript源码转换为抽象的语法树(Abstract Syntax Tree/AST)
2.Ignition:解释器,将AST转换为Bytecode,并解释执行Bytecode;此外还会同时收集TurboFan优化编译所需要的信息,比如函数参数的类型
3.TurboFan:编译器,利用Ignitio收集的类型信息,将Bytecode转换为优化后的汇编代码(Optimized Machine Code/v8里将汇编代码称作machine code)
4.Orinoco:Garbager Coollector(GC),垃圾回收部分,负责将程序不再需要的内存空间回收
原理如下
1 | javascript ----> Parser ----> AST -----> Ignition --------------> Bytecode ------> 运行结果(Ignition直接运行Bytecode) |
Parser
Parser的部分源码如下
1 | FunctionLiteral* Parser::ParseProgram(Isolate* isolate, ParseInfo* info) { |
parser在生成AST之前,会调用scanner_.Initialize进行词法分析将javascript转化为有意义的代码块(Token),然后parser再将Token解析成AST
比如var answer = 6 * 7;进行词法分析后的token如下(在线网站:https://esprima.org/demo/parse.html#)
1 | [ |
生成的AST如下
1 | type: Program |
Pre-parser
例子如下
1 | function func1() { |
v8并不会直接解析代码中的所有函数,对于函数申明,会使用pre-parser进行预解析,而遇到立即调用的函数表达式(IIFE)
会调用parser完全解析函数,并生成AST。
pre-parser需要做的事情有:验证它跳过的函数在语法上是否有效,并生成正确编译外部函数所需的所有信息。当稍后调用预先解析的函数时,它会根据需要
进行完全
解析和编译。
关于惰性parser例子如下
1 | // This is the top-level scope. |
outer直接指向外部context,该context包含内部函数使用变量申明的值。为了允许函数的惰性编译(并支持调试器),上下文指向一个名为ScopeInfo。
ScopeInfo对象描述了上下文中列出的变量。这意味着在编译内部函数时,我们可以计算变量在上下文链中的位置。
关于per-parser更详细的信息见:https://v8.dev/blog/preparser
Parser
javascritp代码中,立即调用的函数表达式(IIFE)由parser将其进行完全解析,并生成AST
Ignition
Ignition 解释器本身由一系列字节码处理程序代码片段组成,每个片段都处理一个特定的字节码,然后调度给下一个字节码的处理程序。这些字节码处理程序使用高
层级的、机器架构无关的汇编代码写成,由 CodeStubAssembler 类实现,并由 TurboFan 编译。
在2017之前v8使用full-codegen+Crankshaft 生成machine code,不生成bytecode,之后设计了Ignition,通过生成bytecode的方式节省空间与时间
AST到bytecode的流程大致如下:
1 | Parser --> AST --> Bytecode Generator --> Register Optimizer --> Peephole Optimizer |
1.Bytecode Generator:作用是遍历AST,并为每个子节点生成Bytecode
补充:Bytecode Generator本质是一系列字节码处理片段,是用与机器架构无关的高级别的汇编代码写成的,由CodeStubAssembler 实现并由Turbofan编译
更多细节参考:https://www.youtube.com/watch?v=r5OWCtuKiAk&t=1062s 以及https://zhuanlan.zhihu.com/p/41496446
TurboFan
TODO:https://paper.seebug.org/1936/ (简单理解)
object
关于V8对象的部分继承关系如下
1 | TaggedImpl ------> Object -----> Smi |
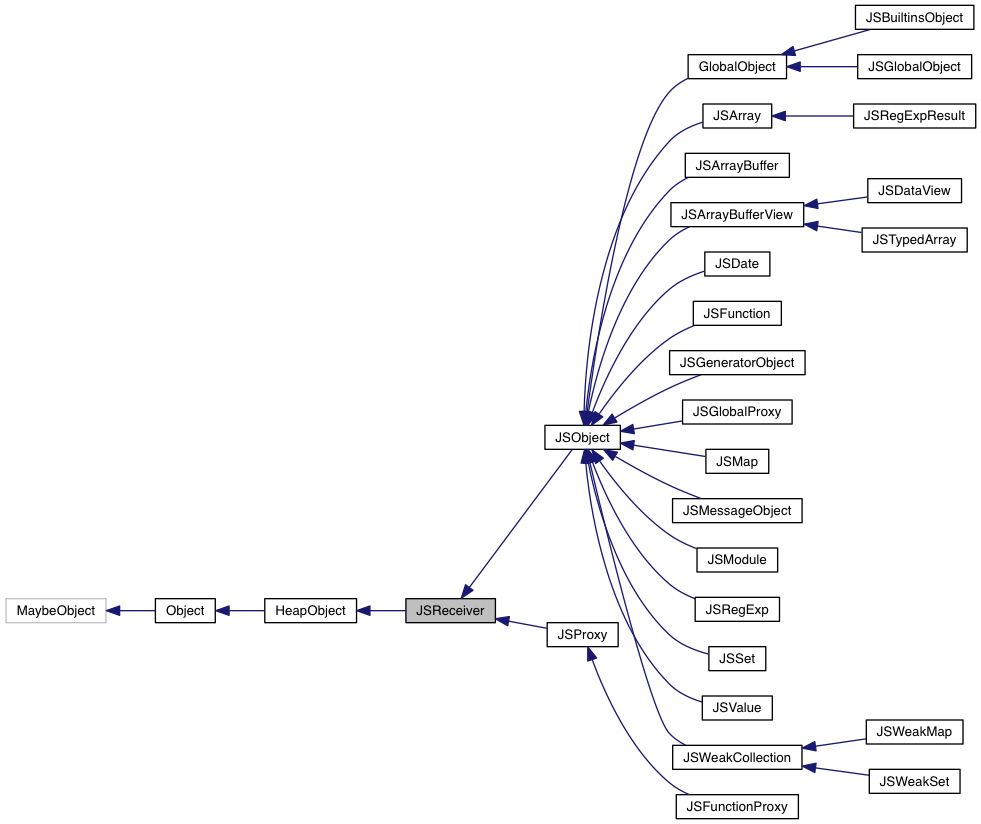
这个图非常的直观
TaggedImpl
TaggedImpl的作用是识别Pointer和Smi(为了GC的准确垃圾回收+节省空间),通过利用地址按字长对齐的特性,v8中相关处理如下:
1.整数往左移1位,最后一位为0,则表示数值
2.指针由于最后一位本来就是0不用改变,即设置为1
HeapObject
heapobject 的编码方式如下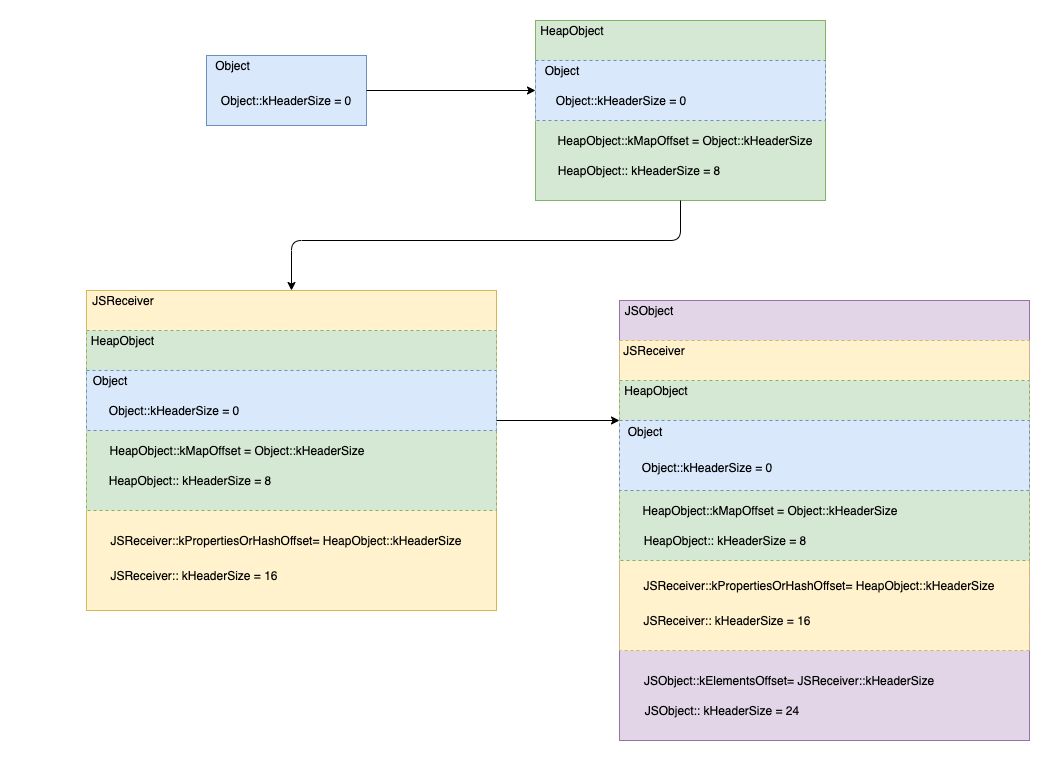
其中Object包括的内容有:
Object::KHeaderSize = 0
HeapObject:
增加了kMapOfset、此时kHeaderSize=8
JSReceiver:
增加了KProperiesOrHashOffset,此时KHeaderSize = 16
JSObject:
增加了KElementsOffset,此时KeaderSize = 24
此时JSObject拥有三个内置的属性:
1.map
2.propertiesOrHash
3.elements
JSReceiver
JSReceiver在堆上的形式,如下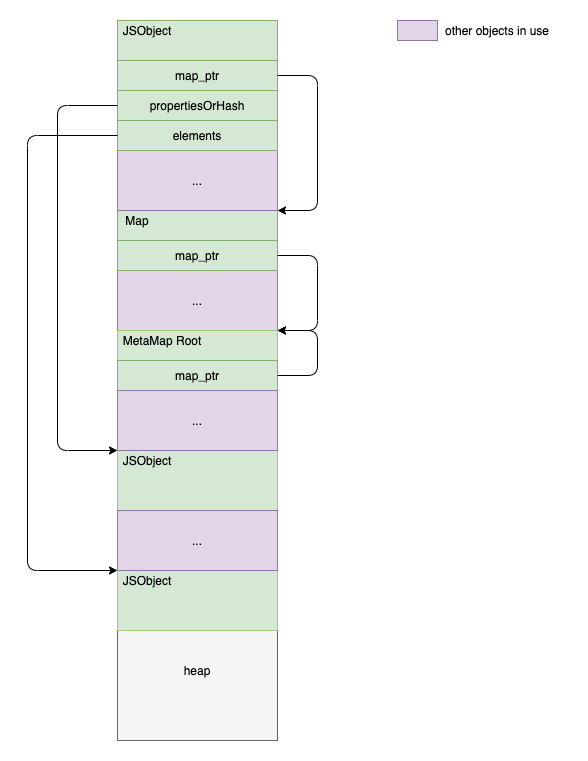
JS中数组和字典在使用上区别不大,当时根据v8实现的角度,在其内部位数组和字典选择不同的数据结构可以优化它们
的访问速度,所以分别使用propertiesOrHash和elements这两个属性,这两个都是指针,v8会根据实际情况将它们
连接到堆上的不同的数据结构
Map
Map的内存拓扑图,如图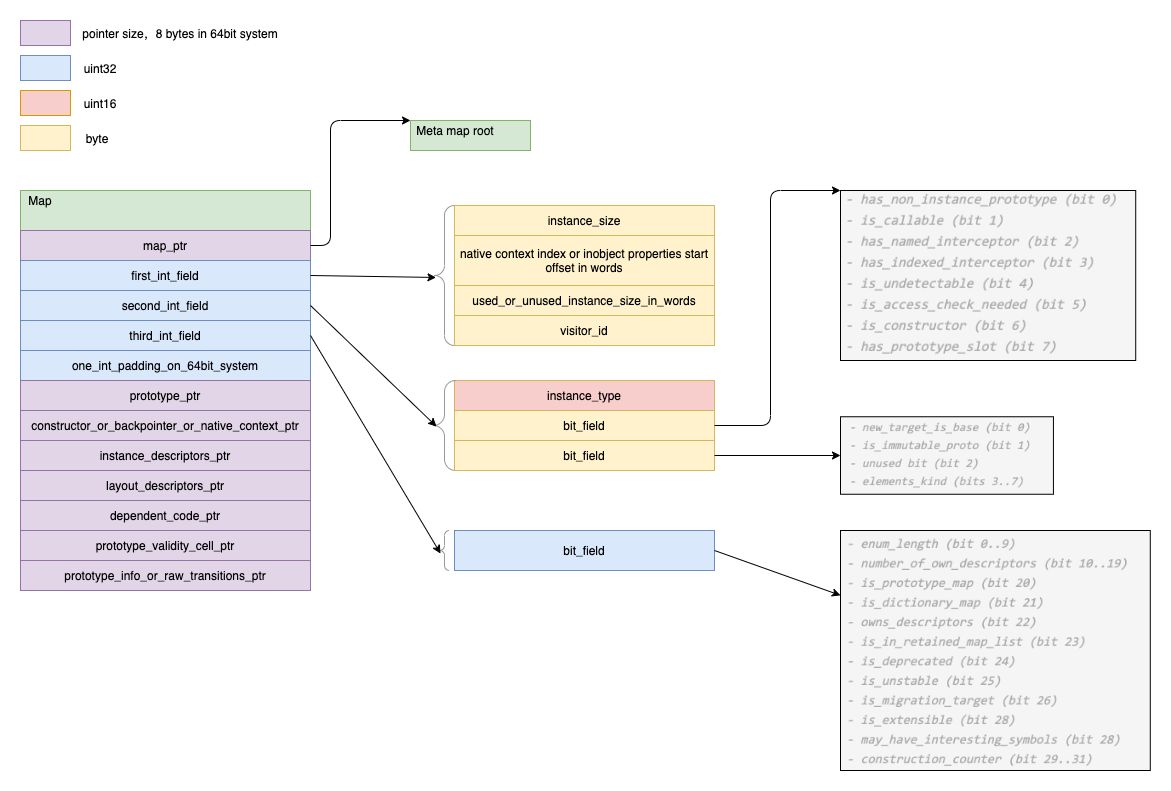
map称作hidden class,用于描述对象的元信息,比如instance size
如图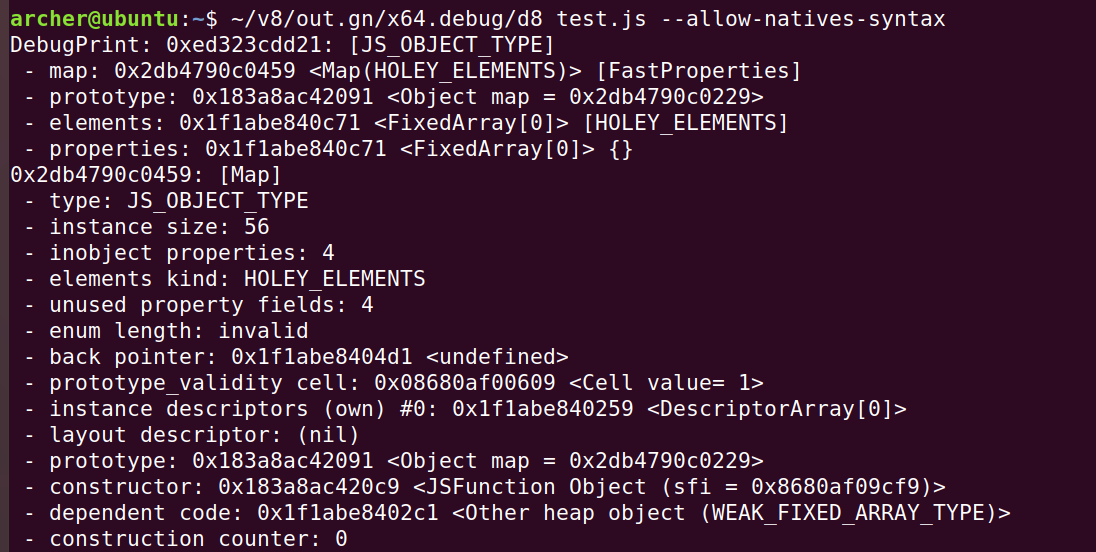
ArrayObject
js中数组的类型很多有:
1.PACKED_SMI_ELEMENTS
2.PACKED_DOUBLE_ELEMENTS
3.PACKED_ELEMENTS
4.HOLEY_SMI_ELEMENTS
5.HOLEY_DOUBLE_ELEMENTS
n…
各类型可以相互转换如图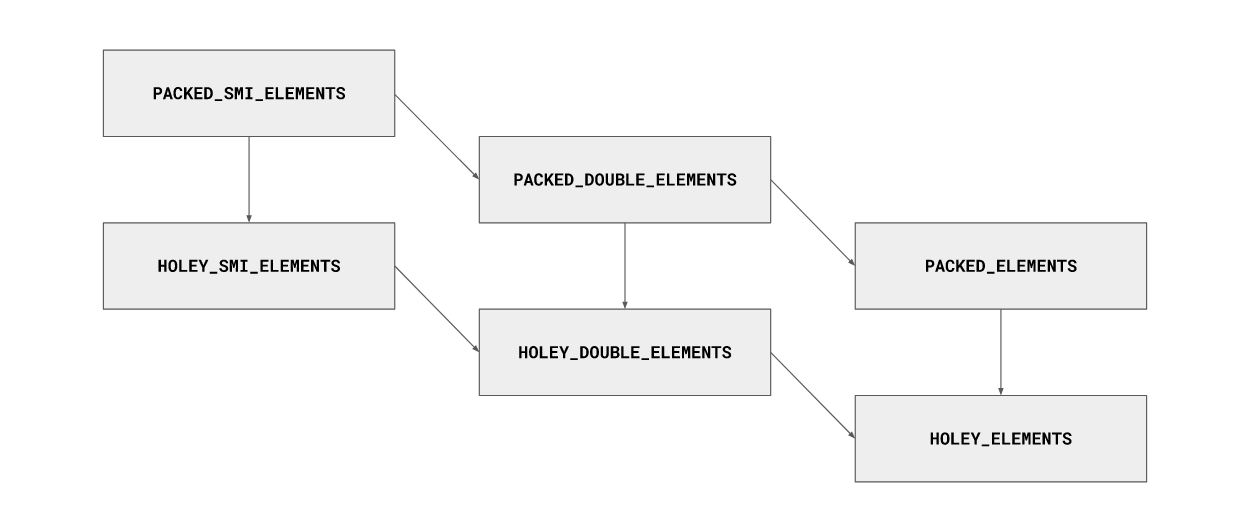
packed的实际意思是连续的数组,HOLEY表示不连续的数组
编写test.js测试
1 | var a = [1,2,3,4,5,6,7,8]; |
jsarray如下
1 | DebugPrint: 0x1d66b9d4ddc9: [JSArray] |
此时看一下elements,如下
1 | pwndbg> job 0x1d66b9d4dd31 |
内存中的组成为:map + properties + elements + length +
inobject、fast、slow
inobject、fast、slow是对象的三种命名属性类型:
1.inobject直接储存在对象本身
2.fast属性储存在属性中,需要通过map中的描述信息访问对应的信息
3.slow属性储存在self-contained属性子弹中,元信息不通过map共享
inobject和fast适用于静态场景(不会发生比较多的属性添加),slow适用于动态场景(比如频繁添加属性、以及delete等操作),并且inobject和fast
都有着一定的配额当创建对象时,会为对象分配额外的配额,添加属性会根据配额设置位对应的属性。
inobject和fast的形式如图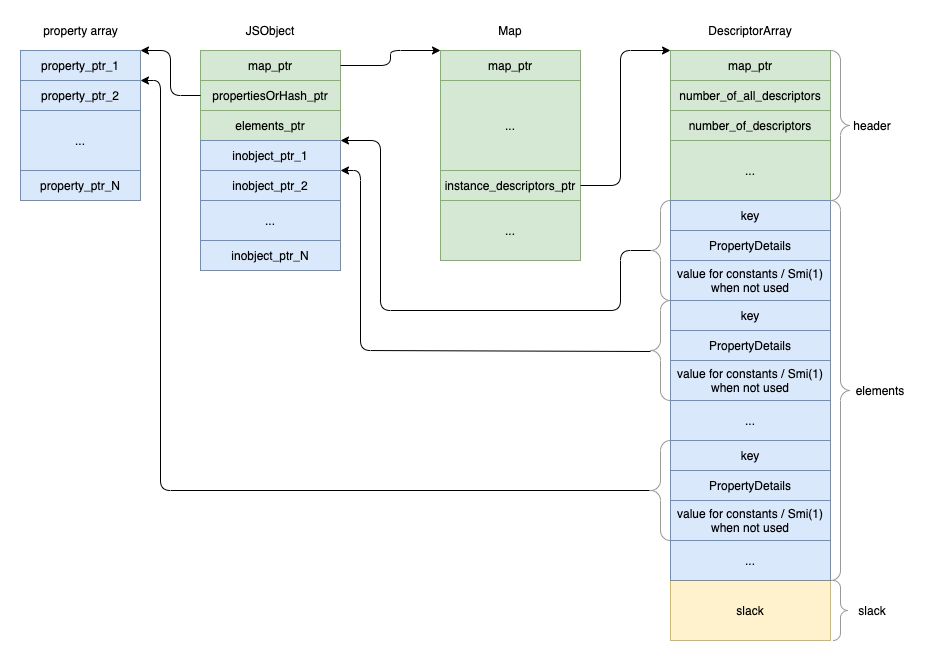
slow形式如图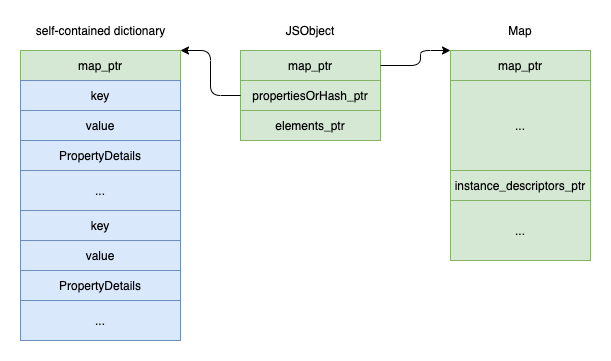
inobject和fast以及slow这三种形式,v8引擎会根据情况切换(执行了delete等操作)
补充:创建对象时会为对象分配额外的inobject配额,如果此时分配的inobject没有被适用,会造成空间的浪费,此时v8使用了名叫slack tracking的技术
slack tracking
slack tracking实现方式如下:
1.构造函数对象的 map 中有一个 initial_map() 属性,该属性就是那些由该构造函数对象创建的模板,即它们的 map
slack tracking 会修改 initial_map() 属性中的 instance_size 属性值,该值是 GC 分配内存空间时使用的
2.当第一次使用某个构造函数 C 创建对象时,它的 initial_map() 是未设置的,因此初次会设置该值,简单来说就是创建一个新的 map
对象,并设置该对象的 construction_counter 属性
3.construction_counter 其实是一个递减的计数器,初始值是 kSlackTrackingCounterStart 即 7随后每次(包括当次)使用该构造函数创建对象,
都会对 construction_counter 递减,当计数为 0 时,就会汇总当前的属性数(包括动态添加的),然后得到最终的 instance_size
slack tracking 完成后,后续动态添加的属性都是 fast 型的。
construct_counter计数形式如下图: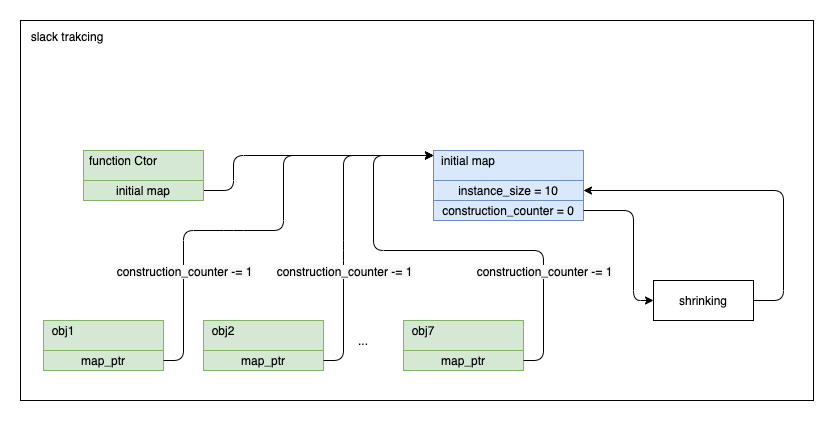
Others
指针压缩
v8 8.0中为提高64位机器内存利用率而引入的机制。
引入指针压缩前的对象布局,如图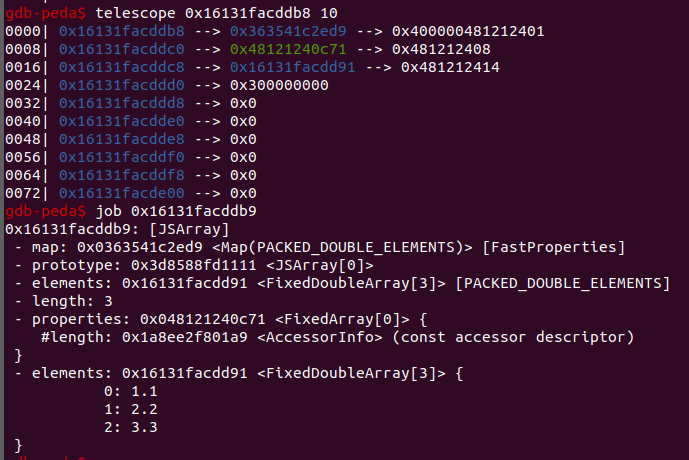
引入指针压缩后,如图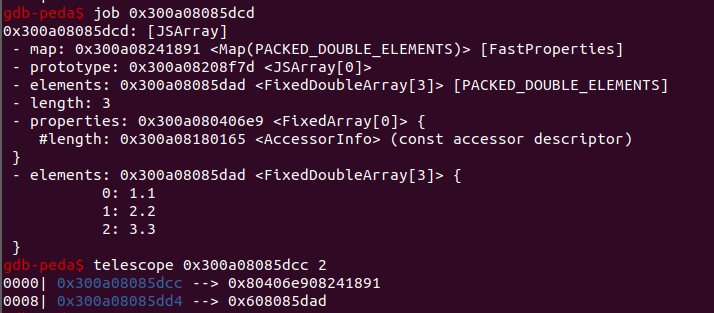
此时实际的指针位R13 + half_point